Let`s jump on it...
Installation
first, we will need to install tree-garden
npm i tree-garden
should do the trick - as long as you are not using yarn 
tree-garden has no dependencies an no peer-dependencies, which should help with maintenance, security and bundle size - feel free to check on bundlephobia 😉
Simple prediction model
Do you like tennis?
Well, I don`t like tennis, but i have tennis data set!
if we want to do some fancy machine learning, we need a couple of things:
- Some data from past - data set
- Some algorithm or way how we turn this data set into predictive model
- Also, some samples that we want to predict using our new model!
- As data set we have simple data set, with records if we go to play tennis dependent on weather. It should look like:
| Outlook | Temperature | Humidity | Wind | Did I play tennis? |
|---|---|---|---|---|
| Sunny | Hot | Hight | Weak | No |
| Overcast | Hot | Hight | Weak | Yes |
| Rain | Cool | Normal | Strong | No |
| ... | ... | ... | ... | ... |
You can see whole data set here
- Algorithm will be default tree-garden configuration
- Sample for testing will be current weather:
const sample = { outlook: 'Rain', temp: 'Mild', humidity: 'Normal', wind: 'Weak' }
Code
import {
buildAlgorithmConfiguration,
growTree,
getTreePrediction,
sampleDataSets
} from 'tree-garden';
// data set of interest is bundled with tree-garden itself
// [data set]
const { tennisSet } = sampleDataSets;
// configuration that is used for training and prediction
// is 'guessed' from training data itself
// empty object is partial configuration we want to use
// [configuration]
const algorithmConfig = buildAlgorithmConfiguration(tennisSet, {});
// we can check what we got
console.log('Config:\n', algorithmConfig);
// lets train decision tree
// [tree]
const tree = growTree(algorithmConfig, tennisSet);
// see how tree looks like?
console.log('Tree:\n', tree);
// our sample of interest
// [sample]
const sample = {
outlook: 'Rain', temp: 'Mild', humidity: 'Normal', wind: 'Weak'
};
// [result]
const shouldWeGoToPlayTennis = getTreePrediction(sample, tree, algorithmConfig);
console.log('Result:\n', 'Should i stay or should i go?', shouldWeGoToPlayTennis);
// [output for visualization tool]
console.log('Json output:\n\n', JSON.stringify(tree));
Comments
Tags in comments of presented code
You can notice in comments of code, I let some tags like [configuration] and
[sample] see here .
These tags mean I want to break it down further in comments in docs.
I will do so on multiple places of tree-garden docs.
[configuration]
See page which describes configuration in detail
[data set]
See data set for more information.
[tree]
More information on trained tree can be found here.
[sample]
Sample that we want to classify is based on weather in time of writing.
Joking it is night, and I have no clue what weather is...
Samples in data set and sample which You are trying to predict does not have to be complete (they can have missing fields). Check how to deal with missing values.
[result]
Result of our decision tree which is presented with our sample is either 'Yes' or
'No' - classes found in our training data set. See api docs for getTreePrediction
function.
If you want for instance whole node, where your sample landed, check functions in
predict namespace.
[output for visualization tool]
You can open visualization tool here on codesandbox or full screen,
copy output of JSON.stringify(tree) and paste it into Trained tree text box and push Load tree button.
If you scroll down you should be able to see your first trained tree!
Congratulation! 😉
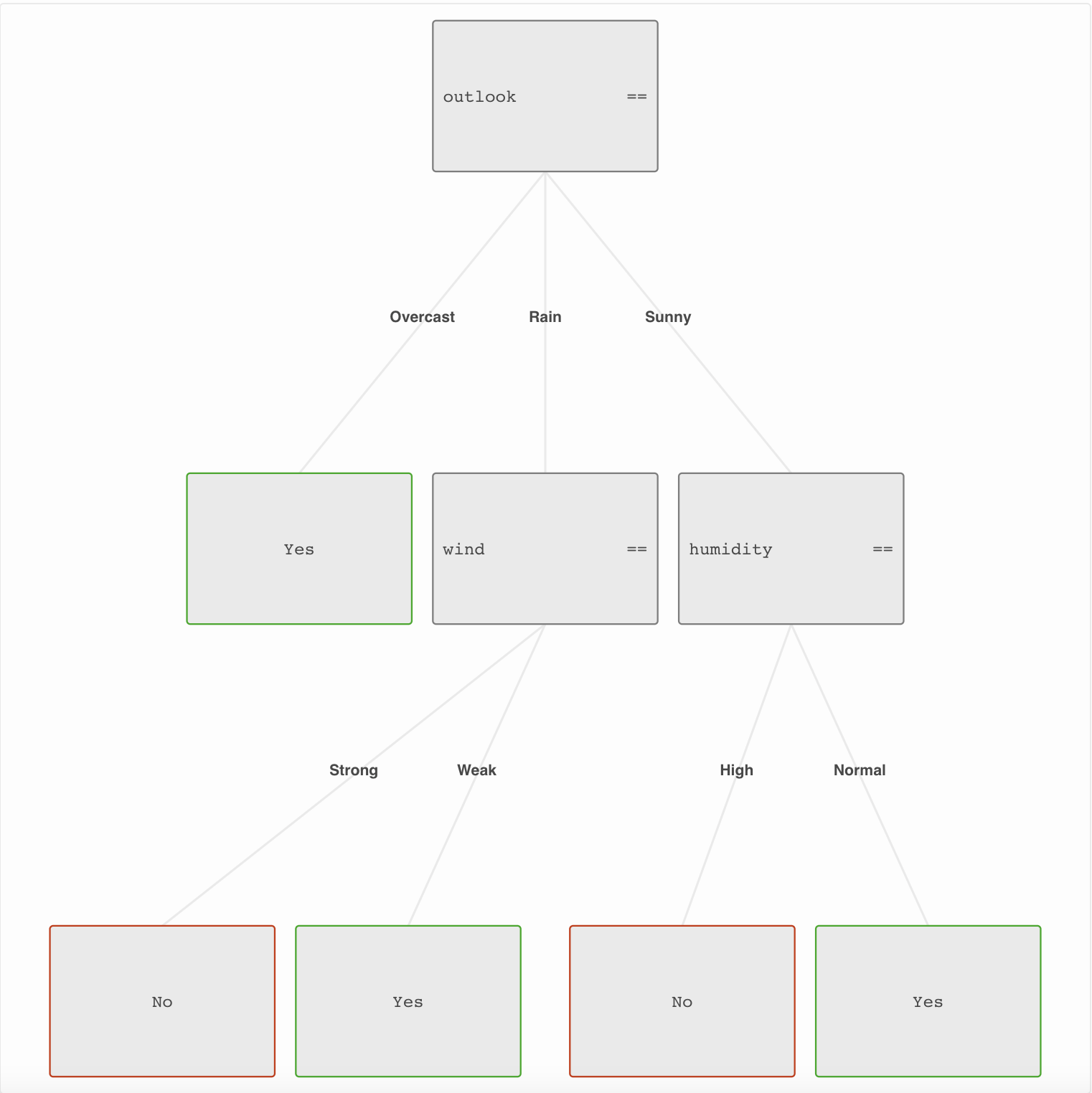
Tree visualization
I used tree garden visualization to produce image of my trained tree
Bit more advanced example
We will now let grow regression tree (tree will predict value not class), that will be able to predict price of houses in
some Indian city, where data come from...
We will need to make some tweaks in configuration to run regression tree - default is classification.
housePrices data set is also packed with tree-garden, let`s see how it looks like:
[
{"POSTED_BY": "Owner", "UNDER_CONSTRUCTION": "0", "RERA": "0", "BHK_NO.": "2", "BHK_OR_RK": "BHK", "SQUARE_FT": "1300.236407", "READY_TO_MOVE": "1", "RESALE": "1", "ADDRESS": "Ksfc Layout,Bangalore", "LONGITUDE": "12.96991", "LATITUDE": "77.59796", "_class": 55.0},
{"POSTED_BY": "Dealer", "UNDER_CONSTRUCTION": "0", "RERA": "0", "BHK_NO.": "2", "BHK_OR_RK": "BHK", "SQUARE_FT": "1275.0", "READY_TO_MOVE": "1", "RESALE": "1", "ADDRESS": "Vishweshwara Nagar,Mysore", "LONGITUDE": "12.274538", "LATITUDE": "76.644605", "_class": 51.0},
{"POSTED_BY": "Owner", "UNDER_CONSTRUCTION": "0", "RERA": "0", "BHK_NO.": "2", "BHK_OR_RK": "BHK", "SQUARE_FT": "933.1597222000001", "READY_TO_MOVE": "1", "RESALE": "1", "ADDRESS": "Jigani,Bangalore", "LONGITUDE": "12.778033", "LATITUDE": "77.632191", "_class": 43.0}
]
You can see, every field except _class is string. This is not ideal as LATITUDE, LONGITUDE and SQUARE_FT are clearly
numbers. We will have to tackle it in configuration as well.
Code of advanced example
import {
impurity,
dataSet,
sampleDataSets,
prune,
statistics,
getTreeAccuracy,
growTree,
buildAlgorithmConfiguration,
getTreePrediction
} from 'tree-garden';
// let`s build regression tree!
// first lets divide data set into two parts - 60% of samples to training set, rest to validation
const [training, validation] = dataSet.getDividedSet(sampleDataSets.housePrices, 0.6);
// how many samples we have in each data set
console.log(`length of validation: ${validation.length}, length of training: ${training.length} `);
// how to turn default configuration to configuration for regression tree?
const myConfig = buildAlgorithmConfiguration(sampleDataSets.housePrices, {
treeType: 'regression', // we have to choose tree type - classification or regression
getScoreForSplit: impurity.getScoreForRegressionTreeSplit, // [split scoring function]
biggerScoreBetterSplit: false, // [split scoring function]
excludedAttributes: ['ADDRESS', 'POSTED_BY'], // lets exclude attributes that will probably not help with accuracy
// data set is not processed in best way - all fields are strings!
// automatic recognition of dataType would not work here
// we can overcome it by setting dataType manually - [force data type]
attributes: {
SQUARE_FT: { dataType: 'continuous' },
LONGITUDE: { dataType: 'continuous' },
LATITUDE: { dataType: 'continuous' }
}
});
// check config
console.log(myConfig);
// let`s grow tree on training data set
const tree = growTree(myConfig, training);
// ouch this tree is big !!!
// if you grow tree without any restriction it usually over-fits training data and also is not useful for data exploration
// [un-pruned tree]
console.log(`Raw tree: Number of nodes,${statistics.getNumberOfTreeNodes(tree)} acc:${getTreeAccuracy(tree, validation, myConfig)}`);
// there is multiple ways how to prune your raw tree [tree pruning]
// after pruning tree is smaller and accuracy on validation data set is better!
const prunedTree = prune.getPrunedTreeByReducedErrorPruning(tree, validation, myConfig);
// lets see how accuracy and size of tree changed after pruning
// [regression tree accuracy]
console.log(`Pruned: Number of nodes,${statistics.getNumberOfTreeNodes(prunedTree)} acc:${getTreeAccuracy(prunedTree, validation, myConfig)}`);
// took one example from data set to use our new regression tree - its price was around 52 - see how close we will be
const myHouse = {
POSTED_BY: 'Owner',
UNDER_CONSTRUCTION: '0',
RERA: '1',
'BHK_NO.': '3',
BHK_OR_RK: 'BHK',
SQUARE_FT: 1181.012946,
READY_TO_MOVE: '1',
RESALE: '1',
ADDRESS: 'Kharar,Mohali',
LONGITUDE: 30.74,
LATITUDE: 76.65
};
// result
console.log('Price of my house will be:', getTreePrediction(myHouse, prunedTree, myConfig));
// let`s output it for visualization
console.log('\n\n\n', JSON.stringify(prunedTree));
Comments on advanced example
[split scoring function]
For regression trees we must set other impurity measuring function than information gain ratio. Check
api doc of getScoreForRegressionTreeSplit
which in a nutshell calculates sum of distances from average value of given tag of samples. For more detailed
information check code or tests of getScoreForRegressionTreeSplit.
Smaller value better split!
Entropy based functions reduce entropy in dataset after split - bigger reduction better split.
In case of regression tree - smaller sum of residuals better split.
[force data type]
If there is the field in data set which type is string ('discrete'), but You see, it can be safely casted
to number ('continuous'), You can do so by manually hinting type for given attribute in configuration.
buildAlgorithmConfiguration function will try
to parse given field as number, if it meets some problematic value (except missing one), it will throw error.
You can also cast attributes in opposite way - force 'continuous' values to behave as
'discrete'.
[un-pruned tree]
If you let grow tree without any limitations, it will usually produce giant tree which is over-fitted towards
training data set.
Such trees have unpleasant properties:
- hard to interpret
- slow, because they are deep
- over-fitted (low accuracy on data they did not see during training)
In our case tree has several hundreds of nodes and accuracy on validation data set is poor.
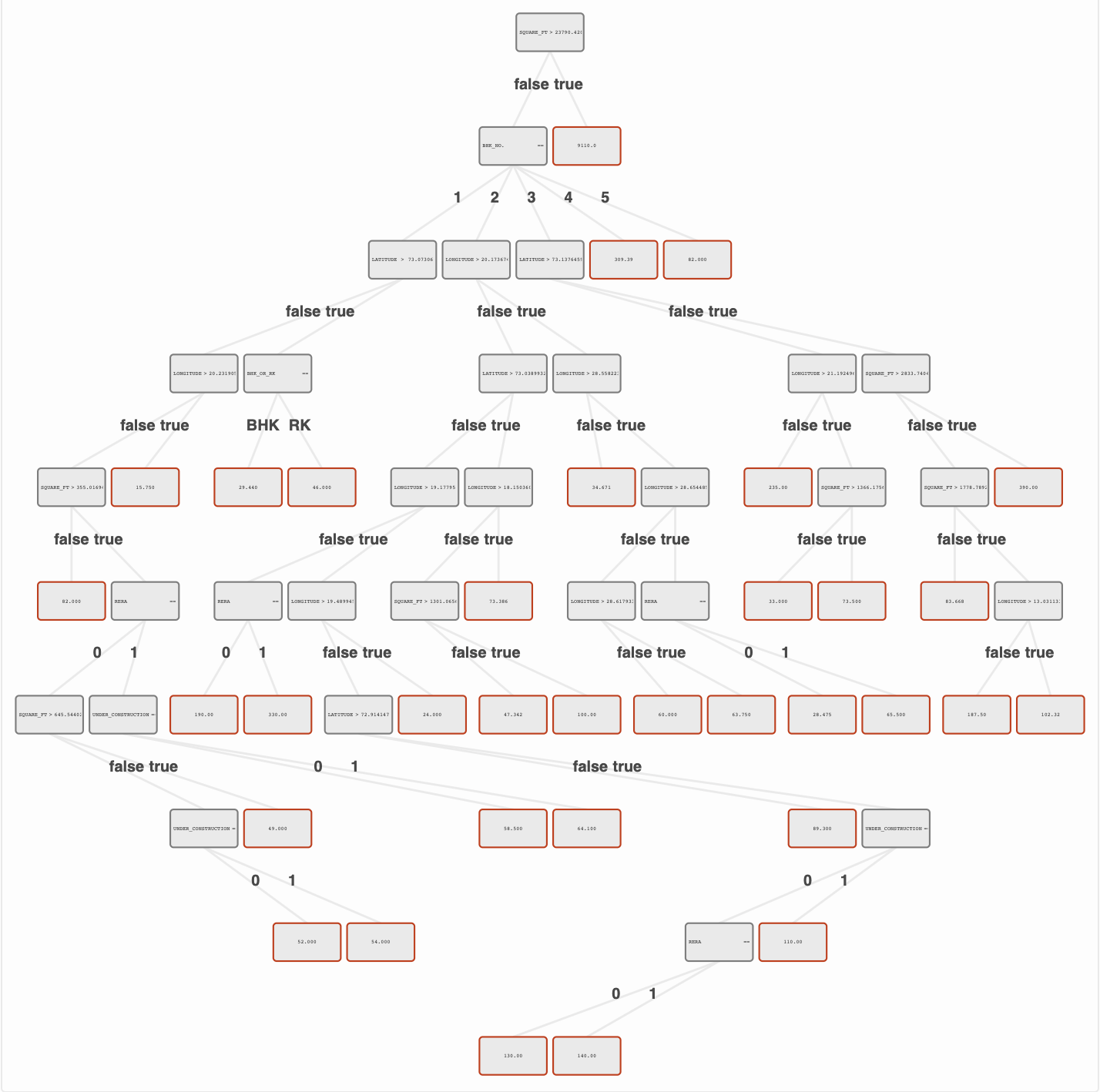
[tree pruning]
In our case, after tree is pruned, number of nodes will decrease 3-4 times, and accuracy on validation dataset will raise. See visualized tree.
Also, please check information on tree pruning.
[regression tree accuracy]
Accuracy is measured differently in case of regression trees. It is similar like R coefficient of linear regression,
but absolute value is used instead of squared one. It is always number up to 1, closer to 1 means
better accuracy. For more information check implementation of getRAbsError.
Visualization of advanced example
Regression tree, we trained and pruned: